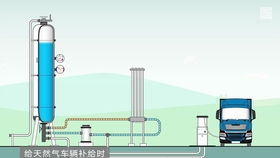
在清潔能源日益普及的今天,液化天然氣(LNG)作為高效、環保的燃料,其儲存設施的安全性和易操作性備受關注。瀏陽市的LNG儲罐,特別是低溫常壓儲罐,以其設計先進、操作簡便的特點,成為能源儲存領域的典范。本文將深入解析其工作原理與操作流程,揭示其背后的科技奧秘。
一、低溫常壓儲罐的基本原理
LNG低溫常壓儲罐是一種用于儲存液化天然氣的專用設備,其核心在于保持LNG在極低溫度(約-162°C)下的液態狀態,同時維持罐內壓力接近常壓。這種設計避免了高壓環境帶來的風險,大大簡化了操作要求。儲罐采用雙層結構,內層為耐低溫材料(如不銹鋼),外層為保溫層,中間填充絕熱材料,有效防止熱量傳入,確保LNG穩定儲存。
二、操作簡單的關鍵因素
- 自動化控制系統:瀏陽市的LNG儲罐普遍配備智能自動化系統,可實時監測溫度、壓力和液位等參數。操作人員只需通過控制面板或遠程終端,即可輕松完成儲罐的充裝、排放和維護,無需復雜手動干預。
- 安全防護機制:儲罐內置多重安全閥和緊急切斷裝置,一旦檢測到異常(如壓力升高或泄漏),系統會自動啟動保護措施,減少了人為操作失誤的可能性。
- 標準化流程:從LNG的接收、儲存到輸出,整個流程都經過標準化設計。操作人員經過基礎培訓后,即可按步驟執行,降低了技術門檻。
- 維護便捷性:儲罐結構設計合理,關鍵部件易于檢查和更換,日常維護工作量小,進一步提升了操作效率。
三、操作流程示例
以LNG充裝為例,操作步驟包括:
- 準備階段:檢查儲罐狀態,確保閥門和儀表正常;
- 連接管道:將運輸車與儲罐接口安全對接;
- 啟動系統:通過控制界面設定參數,自動開始充裝;
- 監控過程:系統實時反饋數據,操作人員僅需觀察確認;
- 完成與斷開:充裝結束后,系統自動停止,斷開連接并記錄數據。
整個過程高效且無需繁復操作,體現了“簡單化”的設計理念。
四、社會與經濟效益
瀏陽市推廣此類LNG儲罐,不僅提升了能源儲存的安全性,還為當地工業和生活用氣提供了穩定保障。操作簡便意味著更低的培訓成本、更高的工作效率,促進了清潔能源的普及,助力節能減排目標的實現。
###
瀏陽市的LNG低溫常壓儲罐通過科技創新與人性化設計,將復雜的技術轉化為簡單可靠的操作體驗。隨著能源轉型的深入推進,這種儲罐必將在更多領域發揮重要作用,為可持續發展注入新動力。對于操作人員而言,掌握其基本原理并遵循標準化流程,即可輕松駕馭這一高科技設備,確保能源供應的安全與穩定。